





Большие данные: новый облик человечества

Забудьте о логике. Забудьте о том, чему вас учили в школе. Инновационные алгоритмы находят в огромном количестве данных тайные модели, которые навсегда изменят наше мышление.


Говорят, при покупке подержанного автомобиля женщин интересует прежде всего цвет, а мужчины обязательно полезут под капот, спросят о пробеге и совершат пробную поездку. Ведь надо же знать, на что способна машина! Есть теория, что мужчинам следует изменить образ мышления.
Во всяком случае, так уверяет американская компания Kaggle: те покупатели, которые приобрели ярко-оранжевую подержанную машину, с техническими проблемами будут сталкиваться в два раза меньше, чем те, которые на цвет внимания не обратили.
Интернет-платформа Kaggle не занимается продажей автомобилей. Она специализируется на объекте, который может перевернуть мир с ног на голову, — на больших данных. Впервые термин «Big Data» был использован для описания неимоверного роста цифровой вселенной.

Объем существующих в мире данных каждые два года удваивается, естественно, не без активного участия Facebook, YouTube и других социальных сервисов. Но массовое информационное помешательство только начинается: «Интернет вещей», уже ставший реальностью на производственных линиях и в логистических центрах, завоевывает повседневную жизнь. В дом, одежду, в воздух и даже в человека — всюду встроены датчики, которые постоянно собирают, хранят и отправляют данные.
Сегодня все знают, что информация — это ценный ресурс. Google и АНБ одним только своим существованием обязаны нашим данным. Одни охотятся за рекламодателями, другие — за террористами; в обоих случаях сопутствующим ущербом является вторжение в личную жизнь. И даже военные технологии и концерны финансовой или автомобильной отрасли уже давно оперируют огромным количеством данных.
Потенциал больших данных огромен, они предвещают ответы на вопросы — еще даже не сформулированные. В гигантских массивах данных таится информация, осознать которую человечеству чрезвычайно сложно. Инновационные аналитические программы способны извлечь эти знания, облачив их в видимую модель.
К примеру, в рамках исследовательского проекта в США была разработана программа диагностики недоношенных детей. 16 различных потоков данных, таких как сердечная деятельность, содержание кислорода в крови и прочие, обрабатываются в режиме реального времени. Таким образом, на каждого грудничка в секунду приходится 1260 наборов данных, анализ которых позволяет распознать инфекции уже за 24 часа до проявления первых симптомов. Врач сумеет принять меры раньше и, следовательно, шансы на успешное лечение выше.
Переворот в мире логики
Большие данные ищут в огромном количестве информации корреляции, незаметные человеку. Нередко эти связи нас ошеломляют, так как мы не можем объяснить их причину — и все же в них есть математические закономерности.

Большие данные способны не только изменить наше мировоззрение, они могут поставить под сомнение само его существование. Анализ данных недоношенных детей показал модель, диаметрально противоположную современной медицинской теории: в преддверии тяжелой инфекции жизненно важные функции недоношенных детей стабилизируются.
Такого рода изменения состояния, которые до сих пор вселяли во врачей спокойствие, при лечении недоношенных детей в будущем можно воспринимать как предупреждение: что-то произойдет со здоровьем ребенка.
В преддверии новых истин
Почему же функции организма младенцев впадают из одной крайности в другую за относительно небольшой промежуток времени, мы так и не знаем. Виктор Майер-Шенбергер предостерегает от поспешных выводов:
Большие данные расширяют наше представление о мире, нам еще предстоит открыть совершенно не изученные взаимосвязи. Однако данные дают нам корреляцию, а не причинность. Мы видим, что происходит, но не то, почему это происходит.
— Виктор Майер-Шенбергер, профессор Оксфордского института Интернета
Австрийский профессор Оксфордского института Интернета, консультирующий организации, власти и предприятия по вопросам больших данных, написал на данную тему две захватывающие книги. Он полагает, что человек зачастую видит только кажущиеся причинные связи, дающие ему иллюзию познания.
В будущем мы постоянно будем применять корреляцию больших данных, чтобы подвергать суровому испытанию действительности наш привычный образ мышления о причинах и следствиях.
— Виктор Майер-Шенбергер, профессор Оксфордского института Интернета
Конечно, размышлять о причинах поразительных результатов больших данных очень интересно. Почему, например, оранжевые подержанные машины должны прослужить дольше остальных? Стартап Kuggle обнаружил эту корреляцию, когда анализировал данные крупного американского автодилера, собранные за десять лет.
Может, из-за яркого цвета такие авто реже попадали в аварии и к моменту перепродажи были меньше повреждены? Или их бывшие владельцы — индивидуалисты, предпочитающие «говорящие» машины и поэтому тщательным образом за ними следившие? Или оранжевые авто были всего лишь запасными у водителей с большим стажем вождения?
Большие данные требуют множества информации, в идеале — в структурированном виде, то есть данные измерений техники или метаданные (телефонные номера и пр.). Тем не менее сегодня можно довольно неплохо обработать даже малоструктурированные или не структурированные данные.
Понимание текста
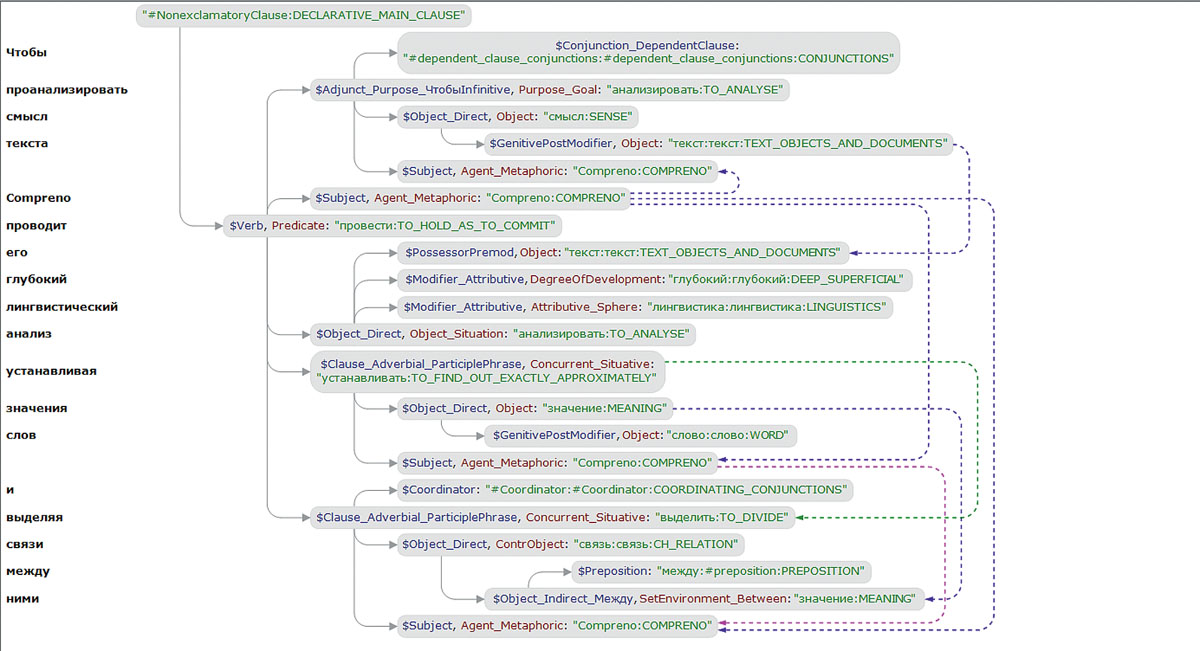
Для обработки массивов данных и выявления закономерностей используется специальное программное обеспечение. Например, компания ABBYY весной 2014 года представила первые решения на базе собственной технологии понимания и анализа текстов на естественных языках Compreno.
ABBYY решает уникальную задачу: учит компьютер понимать смысл текста так, как это делает человек. Таким образом, Compreno выступает в роли лингвистической платформы для решения на качественно новом уровне целого спектра прикладных задач, требующих понимания смысла слов и связей между ними.
Например, это автоматическое извлечение важных объектов (персоны, локации, организации и др.), фактов и событий из потока неструктурированных документов — текстов из блогов и соцсетей, новостей, корпоративной переписки, входящих документов и много другого, а также установление связей в полученных данных — к примеру, по аннотации контракта можно быстро понять предмет договора и какие в нем задействованы стороны.
Facebook, Twitter и другие веб-сервисы автоматически выводят из небрежно написанных пользователями публикаций тенденции или отличительные черты, которые позволяют им получить деньги от рекламодателей. С некоторыми неточностями можно смириться ввиду того, что большая картина благодаря необъятному количеству данных, как правило, ясна. А также потому, что алгоритмы становятся все лучше.
В конечном счете информационная революция приведет к возвращению математики — и к появлению новых профессий.
Специалист по данным и художник по данным — эти профессии можно получить в течение двух-трех лет подготовки, но по причине их междисциплинарного характера это пока невозможно
— Хольм Ландрок, старший консультант компании Experton Group, занимающейся вопросами бизнес-консалтинга.
Специалист по данным, например, должен владеть знаниями в области статистики, информационных технологий, экономики и организации производства, психологии, техники и СМИ. Художник по данным должен разбираться в графическом дизайне, психологии, математике, информационных технологиях и коммуникациях.
Медицина: революционные рецепты
На первый взгляд, большие данные стригут всех под одну гребенку. При более детальном изучении оказывается, что зачастую все как раз наоборот, особенно в медицине: анализы данных могут помочь подобрать лечение персонально для каждого пациента.
«Персонализированная медицина» — это одно из самых громких обещаний информационного будущего. Пациенты с жалобой на насморк обычно получают рецепт на аспирин. Минус такого лечения: врач выписывает рецепт в соответствии с медицинскими указаниями, например, три раза в день по таблетке в течение недели — вне зависимости от пола, возраста, веса и чувствительности к лекарству, не глядя на то, что выздороветь человек может и через два дня, и через семь. Дозировку почти невозможно определить точно.
Майер-Шенбергер пророчит скорый уход от такого рода медицинских единиц.
Каждый организм уникален, каждый реагирует на заболевание по-разному. До сих пор наши врачи не могли подстраиваться под отдельные личности, потому что у них не было достаточно данных, не говоря уже об их анализе. Ситуация меняется у нас на глазах, и не только в высокотехнологичной медицине, но и в банальных случаях типа дозировки лекарства.
— Виктор Майер-Шенбергер, профессор Оксфордского института Интернета
Медицинская аппаратура в стационаре для недоношенных детей выдает огромное количество информации. Датификация людей в медицинских и других целях перестала быть исключительной, например, при обращении в клинику. Фитнес-трекеры и разные приложения на смартфоне, умные браслеты и носимые устройства при помощи датчиков постоянно анализируют данные о состоянии здоровья. Участники современного движения Quantified self как раз и занимаются постоянным сбором данных о собственной жизни до прихода врача или крэша данных.
Если у врача будут все необходимые данные, он сможет изучить корреляции в аналогичных ситуациях и в истории болезни пациента. Майер-Шенбергер рассказывает случай из жизни:
У меня высокий уровень холестерина в крови. Обычно его понижают, принимая лекарства. Но различные анализы показали, что стенки кровеносных сосудов у меня в порядке. Мой терапевт говорит: «Ваш организм работает так, как он должен работать». Понижение уровня холестерина, возможно, вывело бы его из равновесия.
Большие данные были бы идеальным способом индивидуального подхода при подобных сценариях:
Мы должны переосмыслить понятие болезни. Если раньше больным был тот, чьи показатели отклонялись от средних, то в будущем болезнь человека проявится в отклонении его состояния от его обычного. И тогда мой высокий уровень холестерина перестал бы быть болезнью.
Большие данные: образование
Казалось бы, парадоксально: индивидуализация — самый большой козырь больших данных и в сфере образования. Возможно, из-за хронического недофинансирования этой области революции придется подождать подольше, но она обязательно придет. Как и каждый пациент, каждый школьник уникален, даже несмотря на то что уже в течение нескольких сотен лет все ученики одного класса занимаются по одним и тем предметам, получают одинаковые задания, которые необходимо выполнить за определенное время, находясь к тому же в одном помещении.
Современные образовательные организации, как, например, основанная в США Онлайн-академия Хана, исповедуют принцип индивидуализации. Если ученик испытывает трудности с заданием, в дело вступают большие данные: система ищет в базе учебный материал, который наилучшим образом помог бы ученику, — например, нужное объяснение с наивысшей оценкой на форуме платформы.

Данные обращены к ученикам и учителям. Большие данные подбирают обучение для каждого отдельного ученика. Но обучаются также и сами образовательные платформы: от обратной связи с пользователем они только выигрывают, удовлетворяя его желания все больше и больше.
Как и пациент, получающий рецепт, ученик получает индивидуальную программу. Так, если у ученика проблемы с латынью, система просто меняет расписание и занимается с ним. Если ученик не продвигается дальше, платформа дает советы и рекомендации или меняет последовательность изложения материала. По модели, по которой Amazon предлагает книги, цифровой учитель — или же учитель из плоти и крови — предлагает пути решения задачи других учеников.
Скоринг: данные всегда правы
Самая привлекательная черта, свойственная большим данным, — взгляд в хрустальный шар — может быть воспринята как угроза. При наличии нужных данных можно запустить машину времени.
Когда авиакомпании потребуется заменить двигатель? История данных покажет, какие показатели датчиков должны вызывать подозрения. Покупаете косметику без запаха и еще два десятка товаров из рассчитанного алгоритмом набора? Вы уже на четвертом месяце беременности. На вашей страничке Facebook указано, что вы слушаете Бейонсе и читаете Библию? Выпускники средней школы с такими предпочтениями сдают экзамены хуже всех — заявление о поступлении в колледж можно считать отклоненным.
Слушаете Бетховена и Radiohead и читаете «Лолиту» Набокова? Вы — один из лучших, когда сможете приступить к обязанностям? Заключены под стражу и надеетесь на досрочное освобождение? Нам жаль, но ваш криминальный рейтинг более 50%, вы потенциально способны на повторные нарушения.
Многие такие прогнозы выполняются уже довольно давно. Все же знают, какими заоблачно высокими бывают страховые взносы для начинающих водителей. А теперь появляются тарифы на телематические услуги: взносы уменьшаются, когда страхуемый предоставляет данные о вождении страховщику, и, естественно, увеличиваются, если их нет. То же самое возможно и в сфере здравоохранения: нет фитнес-трекера — нет страховки, по крайней мере, хорошей.
Система предсказывания места и времени преступлений, а иногда и субъекта (Predictive Policing) встречается разве что только в кино. Или в цитадели систем наблюдений — Лондоне, Чикаго и Солт-Лейк-Сити.
Самая большая опасность «предсказательной аналитики» (Predictive Analytics) заключается в том, что она отдает преимущество цепочке из единиц и нулей над человеческим опытом и интуицией. Она подрывает свободу мысли и привязывает нас к нашему прошлому.
Если сегодня вы будете искать в Интернете новости о легализации марихуаны, возможно, что завтра вы уже не сможете получить водительские права. Все эти выводы основаны на корреляциях, необязательно по конкретным личным причинам.


Американский супернерд (virgil.gr) исследовал взаимосвязь между результатами выпускных экзаменов 1350 школьников и их музыкальными и литературными предпочтениями. Теперь мы знаем: любители Бетховена и Набокова отличаются живым умом, а поклонники Бейонсе — это совсем другой разговор.
Особенно пышно расцветает так называемый кредитный скоринг. Если вы хотите взять ссуду в банке, вас сканируют алгоритмами до мозга костей. Как правило, применяются исторические значения вероятности. Если программа обнаружит, что кредиторы посчитали ненадежным вашего «цифрового двойника», значит, ненадежным будете и вы.
Вопрос закрыт
Понятие «цифровой двойник» не нужно понимать буквально. Уже давно известно, что для негативного прогноза кредитоспособности достаточно некорректно указать жилой квартал. При некоторых прогнозах учитывается даже операционная система и марка компьютера или смартфона, которые можно определить по MAC-адресу. Отказ в кредите вам могут обеспечить даже фальшивые друзья на Facebook, а также полное отсутствие друзей вовсе.
Последний писк моды — анализ семейного положения на Facebook. Если вы указали «В браке», в кредите вам, скорее всего, откажут. Алгоритму не по вкусу, когда в частных вопросах потенциальный клиент оказывается слишком болтлив. Однако еще меньше алгоритму нравится, когда человек совсем никакой личной информации не выкладывает.
Критика таких прогнозов звучит все громче. Виктор Майер-Шенбергер как автор книг и ученый критически разбирает этические и философские вопросы, которые ставят большие данные. Он настаивает в первую очередь на «цифровой амнезии», на данных со сроком хранения:
Принцип прост: мы храним или передаем информацию не только под именем и прочими атрибутами, но и датой, которую определяем сами. По истечении срока хранения данные удаляются. Во время хранения эту дату мы можем менять в любой момент.
Такой подход обнаруживает огромное дополнительное преимущество: поскольку информация постоянно будет обновляться, ее качество будет увеличиваться. Возможность воплощения теории в практику остается под вопросом: для промышленности это не особо оправданно, да и пользователь не торопится.


Профессор Виктор Майер-Шенбергер известен как ведущий эксперт по большим данным. В своей захватывающей книге «Большие данные: революция, которая изменит то, как мы живем, работаем и мыслим» он рассматривает потенциал и риски информационной революции.
Более реальной кажется вторая идея Майера-Шенбергера — переводить ответственность за данные с первоначального владельца на текущего пользователя. Для крупных концернов это означает не только возможность использования данных и получения прибыли, но и несение ответственности в случаях злоупотребления. Тогда право на информационное самоопределение можно было бы похоронить, если бы оно не умерло давным-давно.
IT-предприниматель из Германии Ивонне Хофштеттер, как и Майер-Шенбергер, эксперт по большим данным с юридическим образованием, в книге «Они знают все» подвергает критике растущий «информационный капитализм» и бездействующую политику.
То, как большие данные поступают с личной информацией, несовместимо с человеческим достоинством; законная защита конфиденциальности — прямая задача государства, и для урегулирования на законодательном уровне нельзя терять времени. Иначе последствия будут труднообратимы.
Дело может простираться до уровня мировой политики. Перед президентскими выборами 2012 года у команды Барака Обамы было достаточно времени для разработки разумной стратегии, потому что с самого начала победа действующего президента, кандидата от Демократической партии, была предопределена.
Руководитель избирательной кампании Обамы Джим Мессина воспользовался новейшими методами бизнес-аналитики, для чего было нанято почти 50 специалистов по данным. Целью было в первую очередь заручиться поддержкой восьми «колеблющихся» штатов («Swing States») — штатов, в которых нет устойчивого преобладания избирателей республиканской или демократической партии, так как судьбу выборов, несомненно, определили бы избиратели именно из этих штатов.
Специалисты Обамы занимались тщательными поисками корреляций между результатами предыдущих выборов и социально-демографическими данными в отдельных избирательных округах этих штатов. Так, можно было описать каждого избирателя и моделировать их статистический профиль. Алгоритм идентифицировал их на основании сотни различных признаков.
Все остальное было вопросом агитации таких неопределившихся — от рассылки электронных писем и общения на Facebook и Twitter до визита домой. Обама получил голоса выборщиков из семи из восьми «колеблющихся» штатов и сохранил свой высокий пост.
Есть ли запасной выход из больших данных?
Если большие данные нарушают тайну голосования и избирают президента, то наверняка в их силах провернуть что-нибудь еще. Руководитель Лаборатории динамики человека Массачусетского технологического института в Бостоне Алекс Пентланд предлагает сначала проанализировать общество — он называет это Reality Mining, сбор данных об окружающей реальности — и только потом начать действовать. Если машина предскажет определенную вероятность того, что человек или группа выйдут из-под контроля, они получат стимул для изменения поведения.

Предлагаемая Пентландом социологическая модель «стимул-реакция-награда» станет антиутопическим кошмаром, если упустить из виду обязательно следующее за этим нарастание интенсивности — негативные меры воздействия, так как постоянно работающий над собой человек когда-нибудь придет к такому моменту, где все равны. Как выражается Майер-Шенбергер, «тогда машины скажут: «Мы выжали из человека все, что нужно было, теперь мы можем его отключить».
Страх перед однородным обществом полностью оправдан, однако человек все же способен направить большие данные в положительное русло. Корреляции и модели данных не могут держать в ежовых рукавицах ни воображение, ни творчество.
Марку Цукербергу, основателю Facebook, которого можно причислить к авторам информационной революции, сколотившим на ней целое состояние, повезло, что во время его учебы в Гарварде в 2002 году предсказательной аналитики еще не было. Хороший алгоритм может идентифицировать кандидата на отчисление, и если бы Цукерберг вылетел из учебного заведения еще тогда, он бы не смог тайком злоупотребить IT-инфраструктурой элитного вуза для своего эпохального социального медиапроекта. Цукербергу везло, потому что он нарушал правила. Интересно, алгоритм распознал бы это?
А Гарварду в свою очередь крупно повезло, что в более позднем отчислении не было отказано по соображениям стохастики. Благодаря истории успеха Цукерберга вырос имидж консервативного элитного вуза. Сегодняшний Гарвард — это рай для начинающих интернет-гениев, который по технологическим исследованиям может конкурировать даже с Массачусетским технологическим институтом в Бостоне и Стэнфордским университетом в Калифорнии.
Не у всех есть задатки нового Цукерберга, Пикассо или Эллы Фицджеральд, но если вы пользуетесь социальным пространством, защищаете свои права и идете собственным путем, вы меняете планы больших данных на мир. Может быть, в целях безопасности нам следует позволить данным говорить самим за себя, чтобы кто-нибудь разработал алгоритм, который предскажет, каким будет наше будущее с большими данными и как снова освободиться от всего этого в случае сомнений?
Фото: компании-производители; aetb, ATLANTISMEDIA, Nenov Brothers/Fotolia.com











 Читайте нас в социальных сетях
Читайте нас в социальных сетях