: что нового в линейке?")





Когда компьютеры научатся видеть?

Специализированные компьютеры уже сегодня могут составить представление об окружающей их обстановке. Сколько еще времени пройдет до того дня, когда машины научатся видеть и познавать мир, как человек?


Видеть надо уметь. Повзрослев, эту способность мы воспринимаем как нечто столь же естественное, как и дыхание. Но ведь дети учатся видеть и истолковывать окружающий мир так же хорошо, как и взрослые, до шестого года жизни. Первые два года уходят на постоянные попытки научиться фокусировать взгляд на предмете.
Кроме того, дети учатся получать пространственную картину окружающего мира. Правый и левый глаз видят изображение по-разному — этот же принцип использует кинематограф с 3D-очками. На основе двух изображений мозг учится получать информацию о глубине сцены и пространственное впечатление об окружающей среде. Той среде, в которой мы способны четко видеть только те объекты, на которые обращаем свой взор. И только по истечении шести лет тренировка глаз и мозга завершается. Компьютеры тоже учатся видеть — уже в течение многих лет.
В 1957 году была запущена первая искусственная нейронная сеть, которая была способна к восприятию
Эта компьютерная модель работы мозга была названа «перцептрон». Перцептрон стал одной из первых моделей нейросетей, а «Марк-1» — первым в мире нейрокомпьютером. Несмотря на свою простоту, перцептрон был способен обучаться и даже распознавал некоторые буквы английского алфавита.

А сегодня мы уже используем, например, функцию распознавания лиц на фотографиях. Правда, это всего лишь программа, упрямо выполняющая заложенные команды. Когда-нибудь на смену ей на наши компьютеры придет нейронная сеть, которая будет подобно ребенку учиться на собственных ошибках и постоянно совершенствоваться, меняя свой код. Чем больше нейронная сеть будет собирать изображений, тем лучше научится распознавать сюжеты, которые мы предпочитаем.
Она станет эдаким экспертом по изображениям, который дает полезные советы, наводит порядок и знает, на что следует обратить внимание. Для воплощения такого комплексного сценария в жизнь нейронные сети надо еще обучать и обучать. Но в течение последних нескольких лет в этой сфере были достигнуты значительные успехи.
В наши дни мы оснащаем компьютеры датчиками, определяющими их положение и движение в пространстве, — неким эквивалентом детского восприятия трехмерности. Пример — камера Kinect от Microsoft, выпущенная несколько лет назад для консоли Xbox, и обозначившая новый тренд. Технология Kinect позволяет управлять игрой с помощью жестов, Google разрабатывает проект Tango, а Intel — новую камеру RealSense. При помощи последних можно будет создавать трехмерные модели окружающей среды на мобильных устройствах.
Планшет Dell Venue 8 7000 при помощи камеры RealSense получает представление об окружающей обстановке, в которой находится. Камеры первого поколения R100 к каждой фотографии, снятой на планшет, дополнительно сохраняют информацию о пространстве — для этого они снабжены тремя отдельно расположенными фотомодулями.

Основная камера, которая находится посередине, отвечает собственно за фотографию. В изображениях с камер, расположенных слева и справа, алгоритм ищет идентичные точки, на основании которых выполняется анализ глубины изображения, опирающийся на принцип триангуляции. На расстоянии от одного метра алгоритм срабатывает действительно точно, однако дальше пяти метров точность существенно снижается.
По желанию владельца планшет Dell на снимке в фотогалерее может измерить расстояние между двумя объектами или определить размеры указанной области. Архитекторы-любители и люди, делающие ремонт в квартире, теперь могут обойтись без рулетки. Достаточно будет один раз сфотографировать помещение.

Пространство как сеть из точек измерения
И это только начало. Точность устройств следующего поколения RealSense 200 будет еще выше: они смогут получать информацию о пространстве при помощи лазеров, которые будут образовывать сеть из контрольных точек, излучая инфракрасный свет. Два ИК-датчика получают эти данные, алгоритм связывает точки в области и рассчитывает глубинную модель окружающей среды, которую можно использовать в дополнение к фотографии.
Программа накладывает на лицо сеть из 78 точек, чтобы определить его положение, форму и даже общее настроение — гнев, радость или печаль. Исходя из изменений цвета кожи лица, она может измерить пульс. Мобильные устройства в будущем будут распознавать состояние владельца или его собеседника, а благодаря нейронным сетям со временем их возможности смогут развиваться.

Но пока что мы не дошли до этого. Как и камеры Kinect, инфракрасные камеры RealSense поддерживают невысокое разрешение: 320×240 или 360×480 точек. Система записывает видео и затем анализирует движения и жесты. При 60 кадрах/с система производит до 18 миллионов операций в секунду по вычислению глубины. Intel рекомендует передвигать устройство с камерой RealSense очень медленно, а объекту съемки вообще желательно находиться в неподвижном состоянии.
Исходя из данных рекомендаций, можно сделать вывод, что аппаратная часть мобильных устройств пространственной ориентации, которая необходима, например, для беспилотного вождения, пока что находится на начальных этапах развития. Еще одна проблема: устройство RealSense нужно уменьшить до такой степени, чтобы можно было встраивать его в смартфоны. Это может сделать проект Google Tango, который должен появиться в бытовых устройствах к концу года.
Пока что в рамках проекта выпущен только один смартфон, оснащенный датчиками, аналогичными RealSense или Kinect. Если пройтись по квартире с таким устройствам в руках, Tango записывает маршрут и параллельно измеряет окружающее пространство. Если по тому же маршруту пройтись обратно, Tango сверяет время и распознает знакомый путь.

К чему же все это? К тому, что через несколько лет, например, беспилотные автомобили, управляемые бортовым компьютером, начнут самостоятельно ездить по дорогам общего пользования. Для того чтобы ориентироваться в постоянно меняющейся окружающей среде, им требуется комплексная аппаратура.
Расчет дистанции на расстояниях примерно до 30 метров может выполнить стереокамера. Камеры также способны распознавать полосы движения и светофоры. Но угол охвата у них небольшой — всего 50-60°. Полное панорамное изображение в 360° беспилотные автомобили получают при помощи лидара (light identification detection and ranging, от англ. «световое обнаружение и определение дальности») — устройства, излучающего лазерные импульсы и измеряющего время их отклика, т.е. время, за которое отраженные от цели импульсы возвращаются на приемник. На расстоянии в пару сотен метров надежность такой системы достаточно высокая.

Однако для беспилотного вождения и этого недостаточно. Бортовой компьютер должен сверять данные с подробной трехмерной картой окружающей среды и для расчета курса получать дополнительную информацию о расположении пешеходных дорожек и дорожных знаках. Кроме того, он должен опознавать людей, велосипедистов и животных, рассчитывать, в какую сторону они движутся.

Саморазвитие нейронных сетей
Нейронные сети ищут ответы на вопросы почти что философского свойства. Например, «Когда лошадь на самом деле можно считать лошадью?» Разработчики подкидывают сетям уйму изображений с лошадьми, по которым они учатся распознавать отдельные характерные признаки этого животного: гриву, хвост, нос, ноги или копыта. После интенсивного обучения сетей они в принципе могут распознать «лошадь», представляющую потенциальную опасность для дорожного движения, так же хорошо, как и мы.
Самым большим прорывом в распознавании объектов стало исследование сверточных нейронных сетей (convolutional neural networks, CNN). Математическая операция, называемая «сверткой», накладывает фильтр вокруг квадрата из пикселей. Сверточный фильтр сличает пиксели в середине квадрата с пикселями по краям и следит за схожестью окружения.
Сверточный фильтр знаком почти каждому. В редакторах изображений, например, Gimp, он используется для увеличения резкости или размытия фотографий. Сверточные нейронные сети повторяют эту операцию много раз, с каждым разом все дальше отдаляясь от исходного изображения и с каждым процессом фильтрации переходя на новый уровень абстракции. Пиксели превращаются в линии, дуги, края и другие признаки, из них составляются глаза, нос, ноги.

Цель фильтров — как можно четче выделить эти признаки. Сверточная нейронная сеть применяет сотни и тысячи параллельных фильтров, определяя, какой из них больше подходит для определенного типа объекта. Под конец фильтрации нейронная сеть работает со все более крупными структурами, и в заключительной фазе она делает вывод: это действительно лошадь.
Ведущие специалисты по сверточным нейронным сетям работают в Стэнфорде и других университетах, но, как правило, их переманивают крупные компании — поставщиках услуг вроде Google, Facebook или Microsoft, которым при помощи этих сетей нужно каталогизировать гигантские коллекции изображений.
Так, в феврале исследователи Стэнфордского университета и Yahoo Labs объявили о совершении прорыва в распознавании лиц: их сверточная нейронная сеть идентифицировала лица с любого угла, даже тогда, когда они были частично прикрыты. Для этого им пришлось создать базу данных из 200 тысяч изображений с лицами и сверх того 20 миллионов фотографий без изображения людей для проверки на соответствие. В процессе обучения было пройдено более 50 тысяч итераций 128 изображений. А Facebook выступила с заявлением, что ее
технология DeepFace в 97,25% из всех случаев верно распознает лицо человека, что всего на несколько процентных пунктов ниже средних человеческих способностей
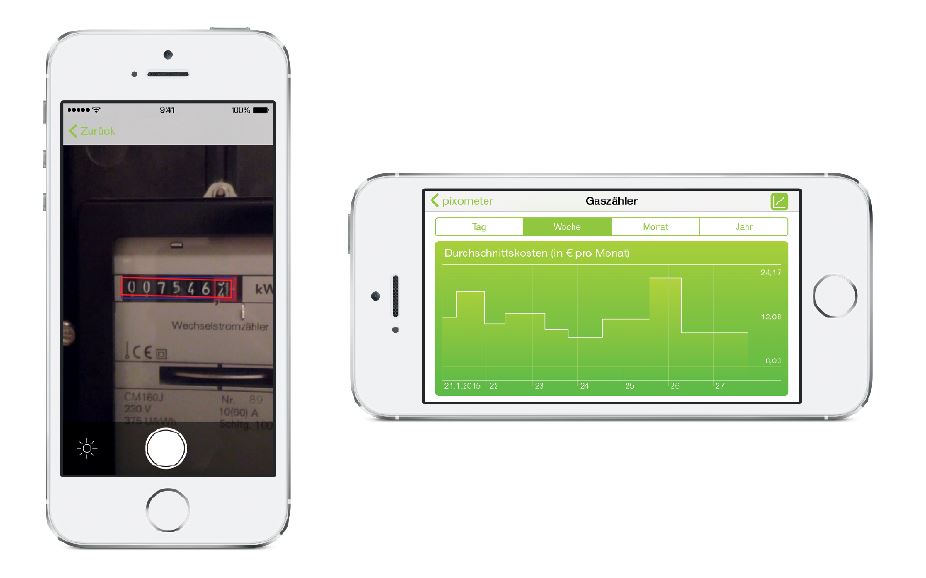
Однако некоторые специалисты скептически относятся к таким сообщениям об успехах. «Даже нейронные сети испытывают трудности при распознавании отдельных объектов в комплексном изображении», — говорит доктор Марк Асбах, получивший ученую степень по теме распознавания лиц и руководивший проектом в Фраунгоферовском институте. В настоящее время он занимается проектом Pixolus, применяющем распознавание объектов в приложении. Если объект находится только в маленьком фрагменте, нейронная сеть анализирует на изображении подчас миллионы фрагментов. «Вместе с тем растет количество возможных ошибочных выводов», — говорит доктор.

И наоборот, сверточные нейронные сети довольно быстро достигают хороших результатов, когда они обучены достижению определенной цели, для которой важным является только ограниченное количество параметров. Исследователям Ратгерского университета в Нью-Джерси удалось научить нейронную сеть распознавать живописца и стиль картины. В 60% случаев сеть верно определяла автора картины, а вот точность определения стиля составила около половины.
Специальные чипы для смартфонов
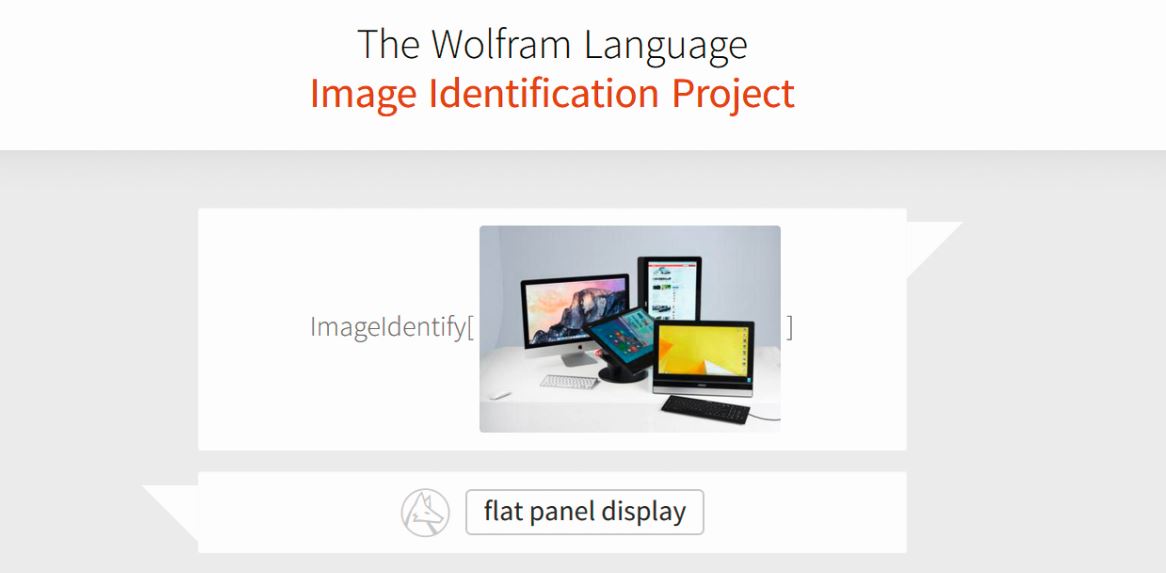
Использование сверточных нейронных сетей не ограничится крупными сервисами. Когда обучение вычислению больших объемов информации завершится, все компьютеры будут использовать их. Очень кстати функция распознавания уже включена в языки программирования, например, Wolfram Alpha.
Разработчику программного обеспечения, который будет добавлять такие элементы в свою программу, не обязательно разбираться во всех их деталях. Компания Qualcomm, лидер рынка по производству мобильных процессоров, даже планирует выпускать для чипов Snapdragon специальные аппаратные модули, которые будут оптимизированы под выполнение многочисленных параллельных операций сверточных нейронных сетей. В течение нескольких следующих лет они станут таким же естественным компонентом, как и сигнальные процессоры на нынешних смартфонах, обрабатывающие аудио и видео.

Развитие сверточных нейронных сетей происходит невероятно быстро. Если еще несколько лет назад они не были фаворитами среди других типов нейронных сетей, то сегодня уже добились лидерства. Следующим шагом в развитии нейронных сетей, похоже, станет способность к самообучению.
Возможно, через пару лет на смену нынешним сверточным нейронным сетям придет новый метод, которому не потребуется помощь человека, подбирающего примеры для обучения. Однако конкретные предложения по такому «обучению без учителя» пока что не появлялись. И значит, пока нельзя еще окончательно ответить на вопрос, когда компьютер сможет видеть так же, как и шестилетний ребенок.
Фото: YouTube/Google ATAP (Aufm.); Intel Corporation; Microsoft Research; Embedded Vision; Velodyne LIDAR; Stanford; Pixolus; Nikolaus Schäffler; Benjamin Hartlmaier; Nguyen, Yosinski, and Clune






 Читайте нас в социальных сетях
Читайте нас в социальных сетях