





Многослойная память для видеокарт

High Bandwidth Memory считывает и записывает данные эффективнее, чем стандартная графическая память. Для этого ячейки видеопамяти располагаются слоями.


Функциональность многих компонентов ПК сегодня ограничена определенным техническим лимитом. Это относится и к чипам, сохраняющим электрический заряд, таким как микросхемы флеш-памяти или ОЗУ. Компьютерная индустрия намеревается отодвинуть границы данного лимита и для этого складывает блоки памяти стопкой друг на друга.
Так, в SSD получилось уместить еще больше данных. Samsung стал первым из производителей SSD, кто сложил в стопки ячейки флеш-памяти и теперь предлагает потребителям диски на 2 Тбайт. Теперь настал черед и микросхем динамической памяти: 3D-RAM не только повышает плотность записи данных, но и становится еще быстрее. Это High Bandwidth Memory (HBM), или память с высокой пропускной способностью.
 Графическая карта AMD R9 Fury X первой делает ставку на новый тип памяти HBM, в котором друг на друга накладывается четыре слоя, что делает Fury более энергоэффективной, чем видеокарты с микросхемами GDDR5, а HBM обеспечивает более высокую скорость передачи данных.
Графическая карта AMD R9 Fury X первой делает ставку на новый тип памяти HBM, в котором друг на друга накладывается четыре слоя, что делает Fury более энергоэффективной, чем видеокарты с микросхемами GDDR5, а HBM обеспечивает более высокую скорость передачи данных.
Превзойти лимит производительности
Сегодня чипы памяти занимают большую часть площади на поверхности печатной платы видеокарты, и на их долю приходится до трети потребляемой видеокартами мощности. В то же время тенденция к совершенствованию графических эффектов, разрешению 4К и использованию очков виртуальной реальности требует еще больше памяти.
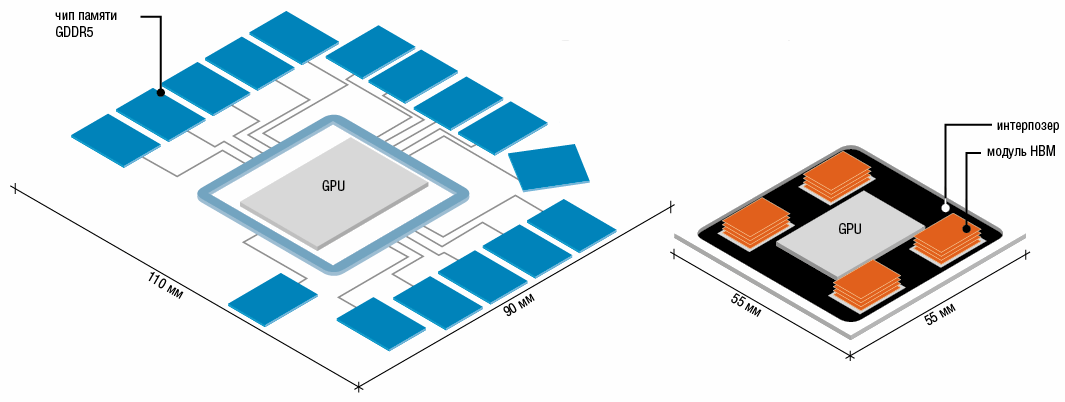
AMD устанавливает на высококлассные карты до 8 Гбайт GDDR5 и для этого группирует вокруг графического процессора 16 кристаллов памяти. Каждый кристалл памяти соединяется с видеочипом тремя линиями. Все линии всех 16 кристаллов образуют интерфейс памяти шириной 512 бит. Больше чипов памяти вряд ли можно поместить на плату, ведь занимаемая площадь и потребляемая мощность ограничены.
High Bandwidth Memory
High Bandwidth Memory выводит параметры подсистемы памяти на новый уровень. Со своим 1024-разрядным интерфейсом (на каждую микросхему, для R9 Fury X суммарно 4096 бит) она вдвое превосходит по показателю ширины шины GDDR5. Добиться этого позволяют две важные инновации: Through-Silicon Vertical Interconnect Access (TSV) и интерпозер (кремниевая подложка).
Чип НВМ первого поколения совмещает четыре слоя микросхем видеопамяти на небольшой площади. В таких видеокартах, как Fury X производства AMD он соединяется непосредственно с графическим процессором. Это снижает энергопотребление и одновременно повышает производительность карты в целом.
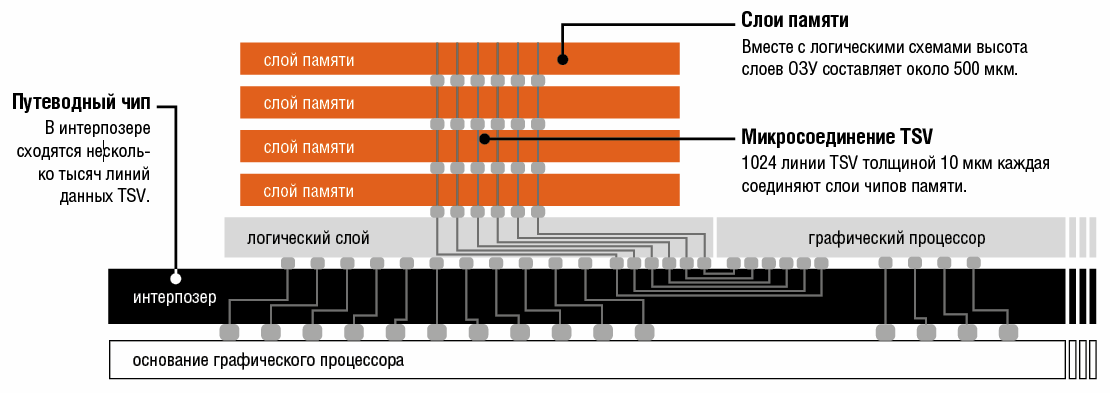
TSV — это маленькие линии данных, проложенные через слои уложенных стопкой чипов. Каждый слой состоит из нескольких пластов, в которых сгруппированы отдельные ячейки видеопамяти. Для TSV в кремнии протравливаются маленькие отверстия диаметром около 10 мкм и после нанесения защитного оксидного слоя заполняются медью.
В качестве концепта или в прототипах 3D-чипов данный подход практикуется уже давно, но теперь он впервые находит применение в серийном продукте. 1024 линии TSV проходят через стопки HBM вертикально сверху вниз через все четыре слоя. На плате они распределены по восьми каналам — каждый шириной в 128 бит. TSV заканчиваются в маленьких контактах (микробампы), которые связывают микросхемы памяти с управляющей логикой.
Передача данных на 5000 линий
Проведение данных от блоков HBM больше не может производиться через стандартные линии данных, ведь от каждого блока HBM к видеочипу идет 1024 соединения. Поскольку графический процессор окружен четырьмя блоками HBM, для передачи необработанных данных требуется более 4000 линий. Сюда же добавляются линии для адресов и управляющих команд, и в итоге доходит примерно до 5000 соединений.
Для транспортировки этого множества отдельных данных требуется новый компонент: интерпозер находится под блоками HBM, а также графическим процессором и соединяет их. При этом речь в принципе идет об отдельном чипе, который не производит вычисления, а только проводит данные. Через сам интерпозер в свою очередь прокладываются тысячи соединений TSV, которые, соответственно, заканчиваются как контакт в микробампе.
Архитектура HBM с интерпозером требует, чтобы графический процессор и память находились в непосредственной близости друг от друга для возможности соединения через короткие линии. Одновременно TSV хорошо отводят тепло.

Посредством расширения интерфейса до 4096 бит можно уменьшить тактовую частоту микросхем памяти по сравнению с GDDR5 и в то же время повысить скорость передачи данных до 512 Гбайт/с, что является рекордом для микросхем динамической памяти. Что касается отрицательных моментов, то придется смириться с тем, что суммарный объем чипов HBM первого поколения не превышает 4 Гбайт. Этого достаточно для актуальных игр и разрешения 4К.
Однако в будущем для активации некоторых функций улучшения графики в разрешении 4K, например, сглаживания по краям, потребуется больше памяти. Для этого производитель чипов памяти SK Hynix разрабатывает версию НВМ 2.0, которая, вероятно, будет применяться в графических картах следующего поколения NVIDIA под названием Pascal, выход которых ожидается в 2016 году. НВМ 2.0 позволит использовать на ускорителе до 8 Гбайт памяти и удвоит скорость передачи данных к видеочипу.
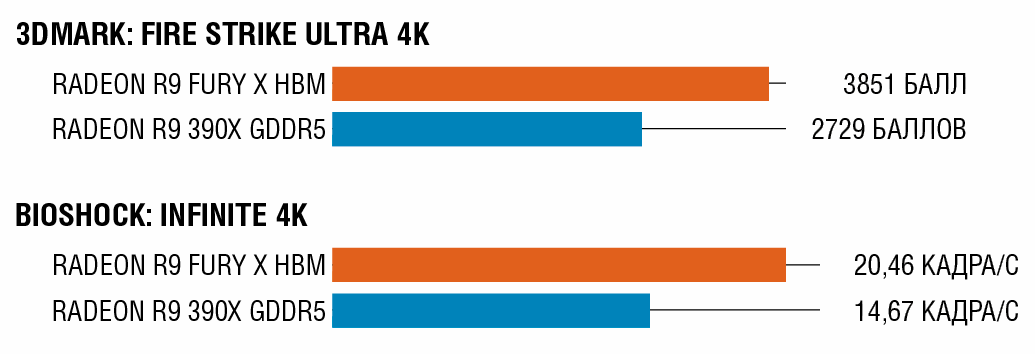
Фото: AMD; Andreia Margarida da Silva Granada






 Читайте нас в социальных сетях
Читайте нас в социальных сетях